Über
Open Notebook - Teil 6
23. Juni 2026 - Lesezeit: 21 Minuten
Speaches
Speaches ist eine freie Software für Audio-KI-Modelle.
Damit lässt sich TTS (text to speech) und STT (speech to text) bereitstellen. Das wiederum kann über die OpenAI-kompatible API an andere KI-Lösungen angeschlossen werden, z.B. Open Notebook. Speaches möchte das Gegenstück zu Ollama sein, dass KI-Modelle für Embedding, Chat, Tools, Vision, Thinking im Angebot hat.
Installationsvorbereitung
Speaches kann am einfachsten über Docker bereitgestellt werden. Dazu kann die bestehende Docker-Bauanleitung für Open Notebook um die Komponenten für speaches erweitert werden.
Zuächst ist der Open Notebook Projektordner für Docker zu öffnen und dort die Datei docker-compose.yml mit einem Texteditor zu bearbeiten.
Mit Nvidia GPU Unterstützung
# Docker Compose - 100% Local AI Setup |
Mit reiner CPU-Nutzung
# Docker Compose - 100% Local AI Setup |
Installation
Dann ist der Projektordner in einer Shell zu öffnen und die Bauanleitung mit Docker auszuführen:
docker compose up -d
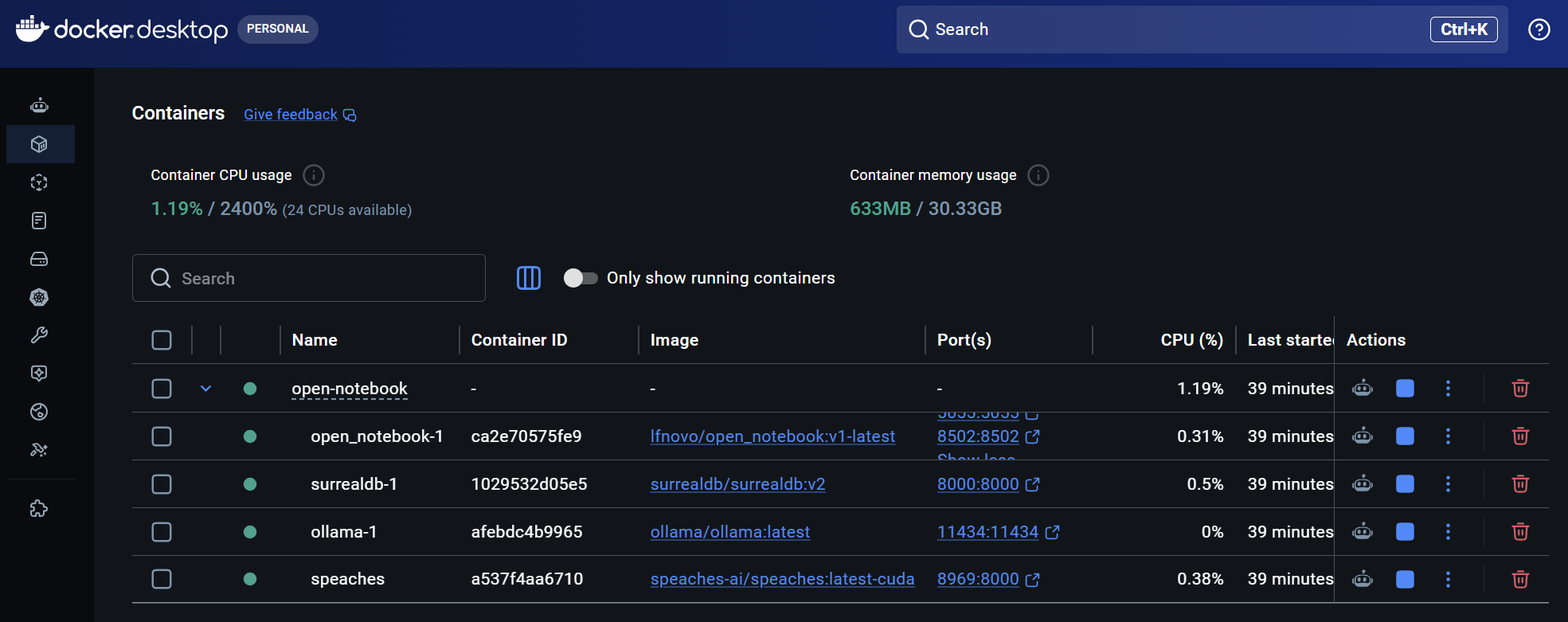
Jetzt laufen Container für Open Notebook, surreal db, Ollama und Speaches.
Welche Modelle für speaches zur Verfügung stehen kann man lokal abfragen mit http://localhost:8969/v1/registry oder über huggingface einsehen.
TTS Modell
Text to speech lokal mit speaches ermöglicht das Erstellen von Podcasts.
docker compose exec speaches uv tool run speaches-cli model download speaches-ai/Kokoro-82M-v1.0-ONNX
Kokoro ist zwar multilingual, enthält aber kein Deutsch. Deshalb noch deutsche Modelle, Piper enthält das:
speaches-ai/piper-de_DE-thorsten-high
speaches-ai/piper-de_DE-thorsten_emotional-medium
speaches-ai/piper-de_DE-thorsten-medium
speaches-ai/piper-de_DE-thorsten-low
speaches-ai/piper-de_DE-mls-medium
speaches-ai/piper-de_DE-karlsson-low
speaches-ai/piper-de_DE-pavoque-low
speaches-ai/piper-de_DE-kerstin-low
speaches-ai/piper-de_DE-ramona-low
speaches-ai/piper-de_DE-eva_k-x_low
STT Modell
Speech to text lokal mit speaches ermöglicht das transkribieren von Video- und Audiodateien als Quellen.
docker compose exec speaches uv tool run speaches-cli model download Systran/faster-whisper-small
Konfiguration in Open Notebook
Modell-Grundkonfiguration
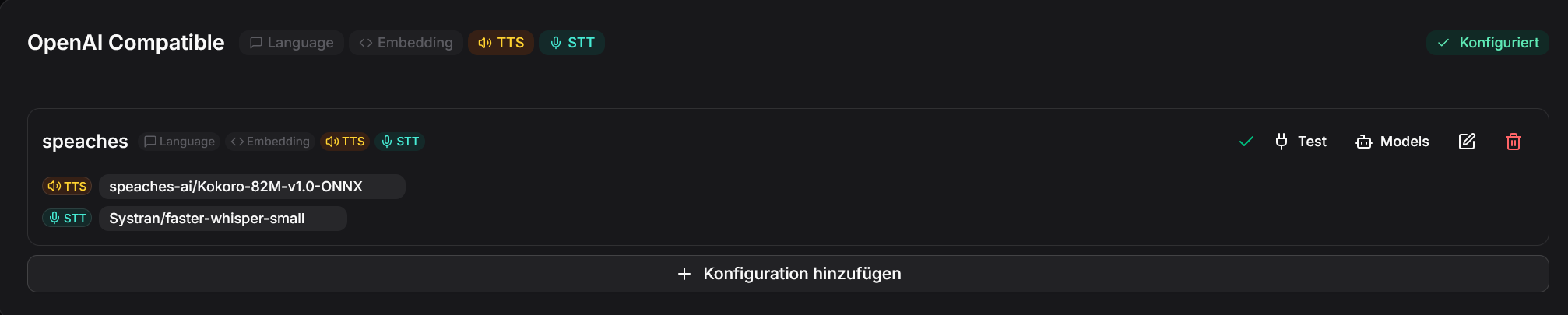
In Open Notebook muß jetzt das OpenAI Compatible Modell eingerichtet werden. Hier gibt man als Namen speaches an und als URL http://host.docker.internal:8969/v1 (MacOs und Windows) bzw. http://172.17.0.1:8969/v1 (Linux). Ein Klick auf Test sollte eine erfolgreiche Verbindung bestätigen.
Mit einem Klick auf Models sit für TTS "speaches-ai/Kokoro-82M-v1.0-ONNX" und für STT "Systran/faster-whisper-small" zuzuweisen.
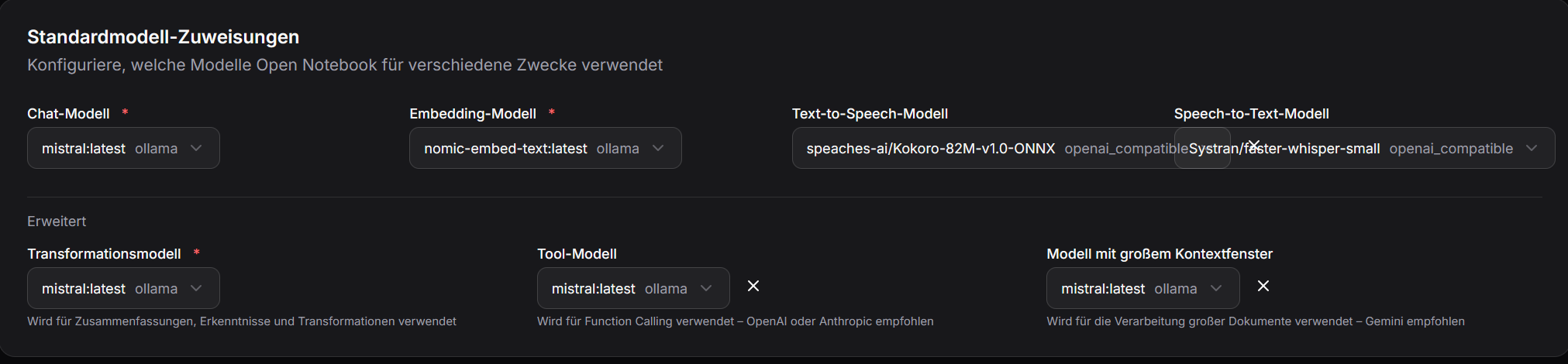
Danach sind die beiden Modelle bei TTS und STT in den Standardmodellzuweisungen auszuwählen.
Podcasts konfigurieren
Unter Podcasts gibt es den Bereich Profile. Dort muß man im Arbeitsbereich folgendes beide Profiltypen konfigurieren. Am einfachsten beginnt man damit bei den existierenden Profilen folgendes zu bearbeiten:
Sprecherprofile
- Stimmenmodell
- Stimmen-ID: manche Stimmenmodelle enthalten mehr als eine Stimme, in der Doku des Modells sind die Namen/IDs der Stimmen mit ihren Eigenschaften zu finden - bei Sprecherprofilen mit mehr als einer Sprecher ist jeweils eine unterschiedliche Stimme zuzuweisen!
- TTS-Überschreibung pro Sprecher: wenn ein Stimmenmodell nur eine Stimme enthält (z.B. bei den Piper-Modellen in Deutsch) kann für jeden Sprecher das Stimmenmodell übersteuert werden
Episodenprofile
- Gliederungsmodell: KI-Modell, dass die Episode in die gewünschte Anzahl an Gliederungspunkten aufteilt
- Transkriptmodell: KI-Modell, dass den finalen, gesamten Episodentext zusammenstellt.
- Podcastsprache: Sprache, in der der Podcast erzeugt werden soll (Achtung! Abhängigkeit: nicht jedes Stimmenmodell unterstützt alle Sprachen!)
Podcast erzeugen
Unter Podcast - Episoden lassen sich einzelne Postcast-Folgen erzeugen.
- auf Podcast erzeugen drücken
- Auswahl der einzubeziehenden Quellen
- Auswahl Episodenprofil
- Episodenname: Festlegung des Podcast-Themas
- Zusätzliche anweisungen: weitere Festlegungen zum Podcast-Inhalt
- Erzeugen

Bei mir wird die Podcast Sprache ignoriert, die Ausgabe ist leider immer in Englisch.
Dazu gab es einen Bug, der eigentlich bereits gefixt sein sollte. Ich habe das mal kommentiert und hoffe auf Fehlerbehebung.
Open Notebook - Teil 5
21. Juni 2026 - Lesezeit: 8 Minuten
Neues Notebook
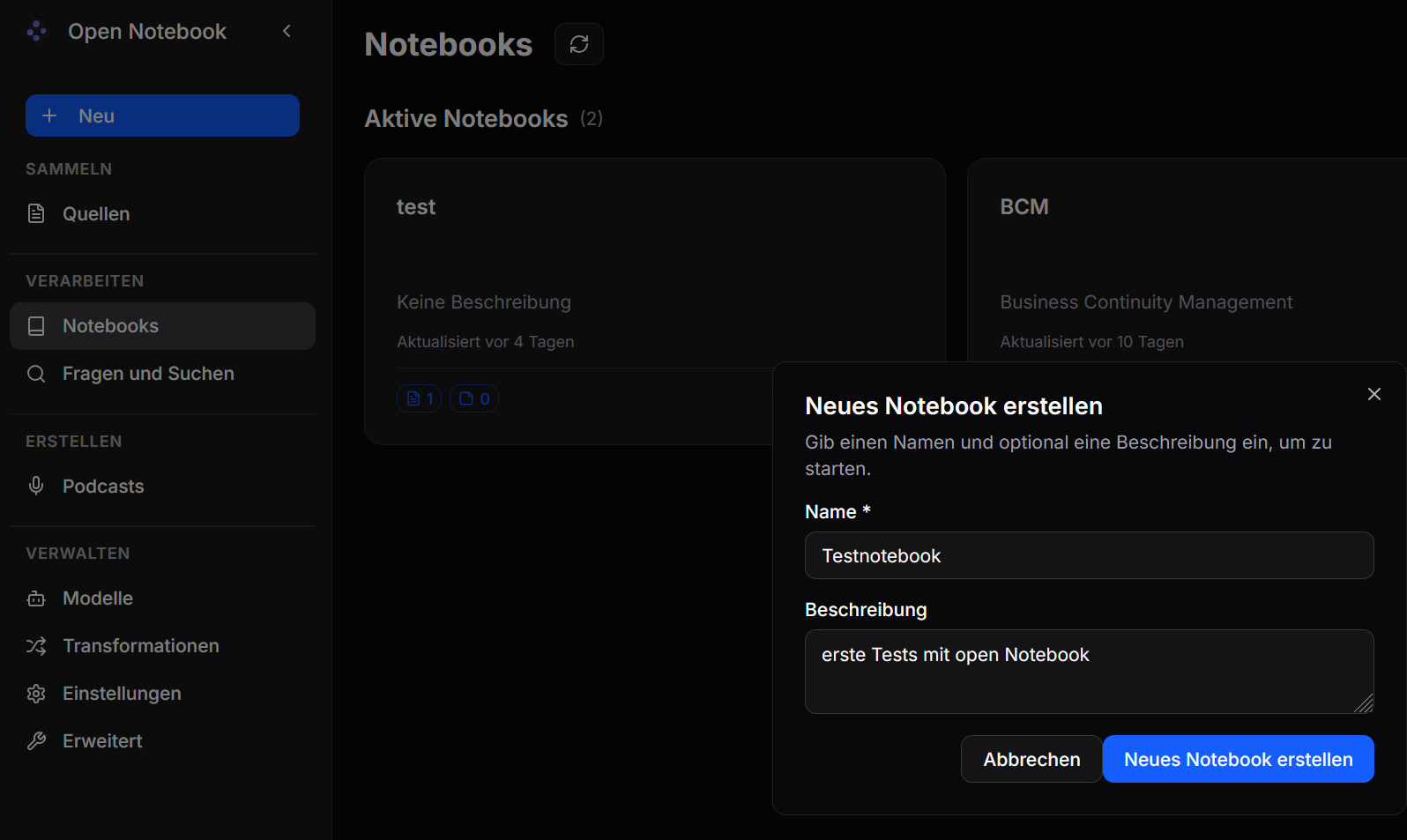
Nachdem die KI-Modelle eingerichtet wurden (außer TTS/STT) kann ein neues Notebook unter Notebooks - Neues Notebook eingerichtet werden.
Quelle(n)
Danach wechselt man in das neue Notebook und fügt eine Quelle hinzu. Am häufigsten wird das wohl ein PDF, Office-Dokument oder eine Website sein.
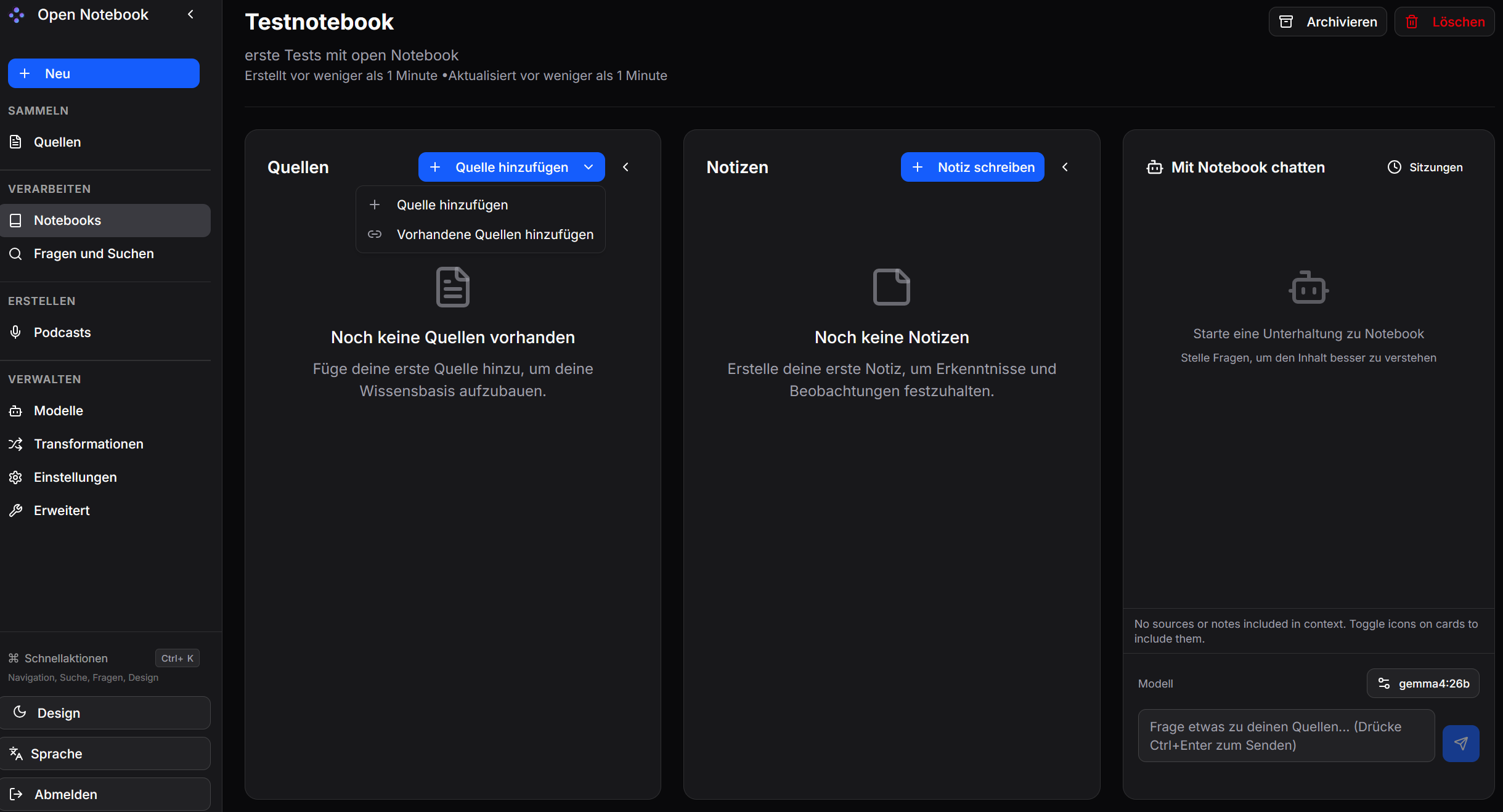
Ich habe zum Test die Website des BSI zum Standard BSI-200-4 hinzugefügt. Man sollte jeder Quelle einen aussagekräftigen Titel geben.
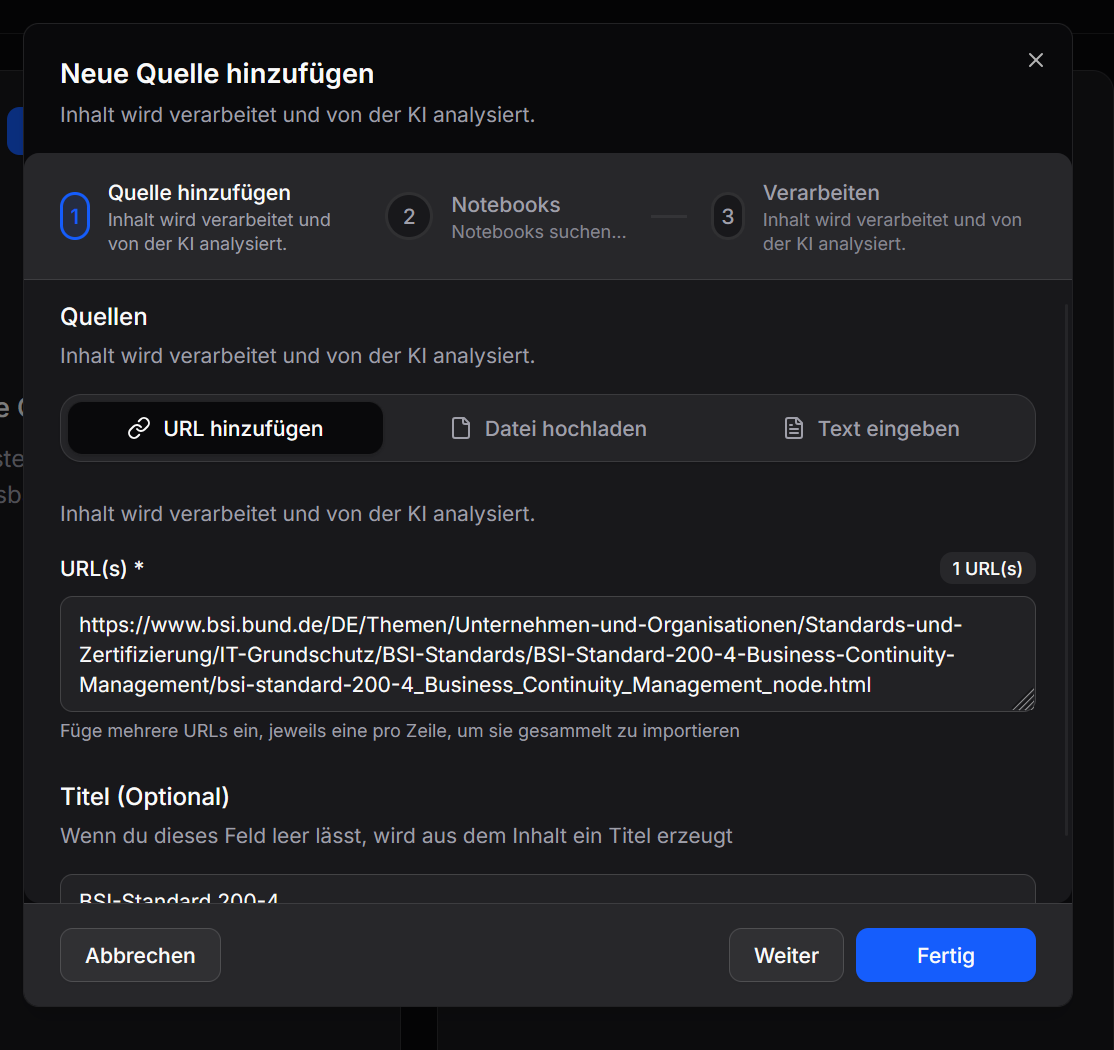

Nachdem die Quelle eingegeben wurde startet die Verarbeitung der Daten im Hintergrund. Hier liest ein integrierter Webcrawler die Website aus und übergibt sie dem KI-Modell für Embedding, das die gesammelten Daten in der Datenbank speichert.
Transformationen
Im Anschluß an Embedding wird automatisiert ein Bericht "dense summary" erstellt. Dazu wird das zugewiesene KI-Modell für Transformationen verwendet. Nach Abschluß erscheint das Ergebnis einer Transformation als "Erkenntnis" neben der Quelle und die Hintergrundverarbeitung ist abgeschlossen.
Die Einstellung zu den verschiedenen Berichten befinden sich unter Transformationen. Dort kann man auch einstellen, ob ein Bericht automatisch beim Hinzufügen einer neuen Quelle erzeugt wird oder ob das manuell gestartet werden soll. Zudem kann man auch eigene Berichte bzw. Transformationen erstellen.
![]()

Verwendung des Notebooks
Ich empfehle in der Dokumentation den User-Guide zu lesen, in dem die Konzepte einzelner Funktionen anhand Beispielen gut erklärt werden.
Chat
Der Chat stellt eine Möglichkeit zur Verfügung interaktiv mit dem Notebook zu arbeiten. Der bisherige Chatverlauf wird dabei auch berücksichtigt, limitiert durch das Kontextfenster des KI-Modells.
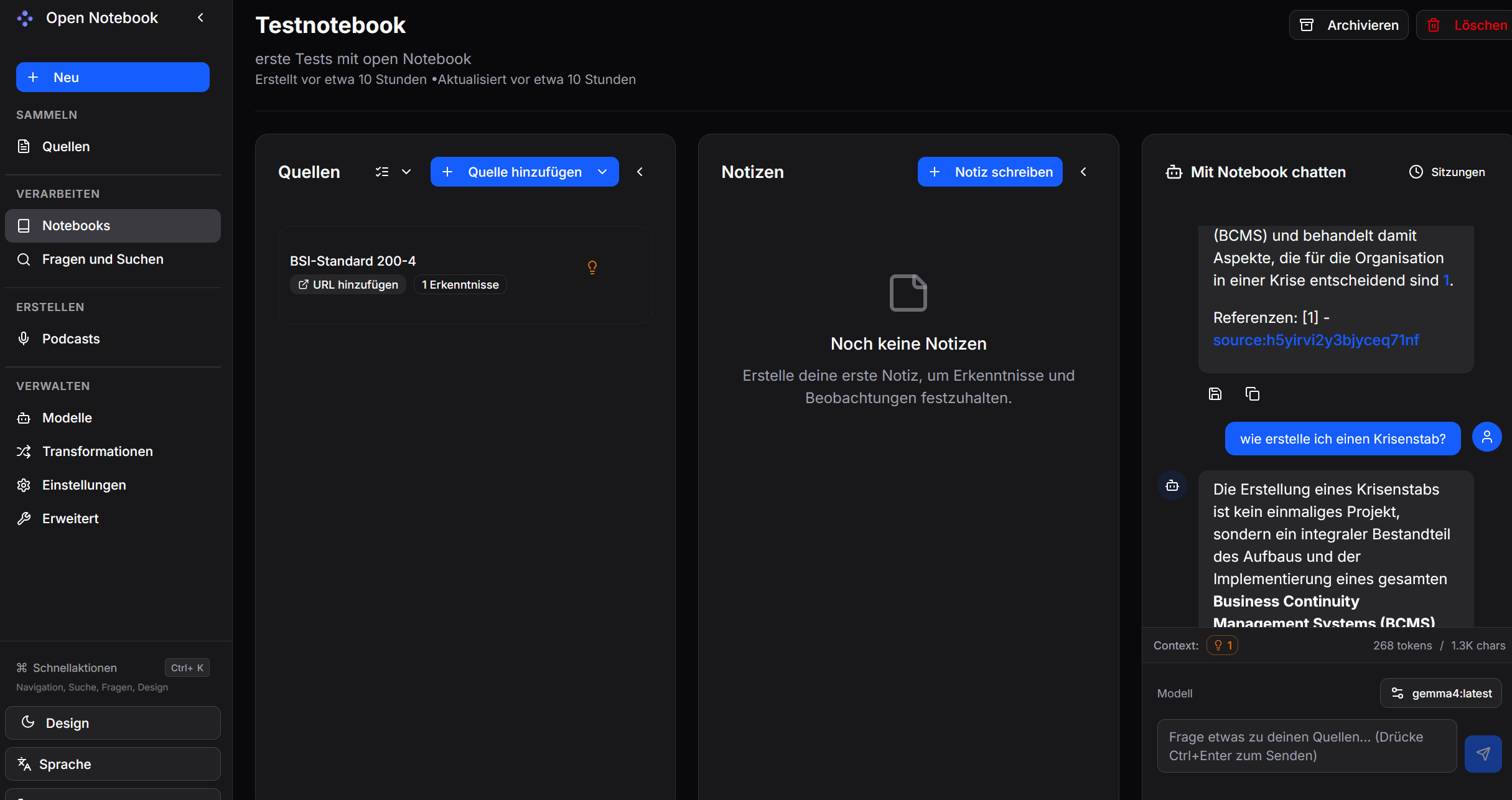
Fragen und Suchen
Bei Fragen und Suchen werden alle Quellen aller Notebooks berücksichtigt. Das ist im Gegensatz zum Chat nicht interaktiv, sondern liefert nur einmal ein Ergebnis.
Wissensbasis durchsuchen
Mit der Option Textsuche werden exakt angegebene Schlüsselbegriffe in der Datenbank gefunden und die Quellen gelistet, in denen ein Treffer erfolgte.
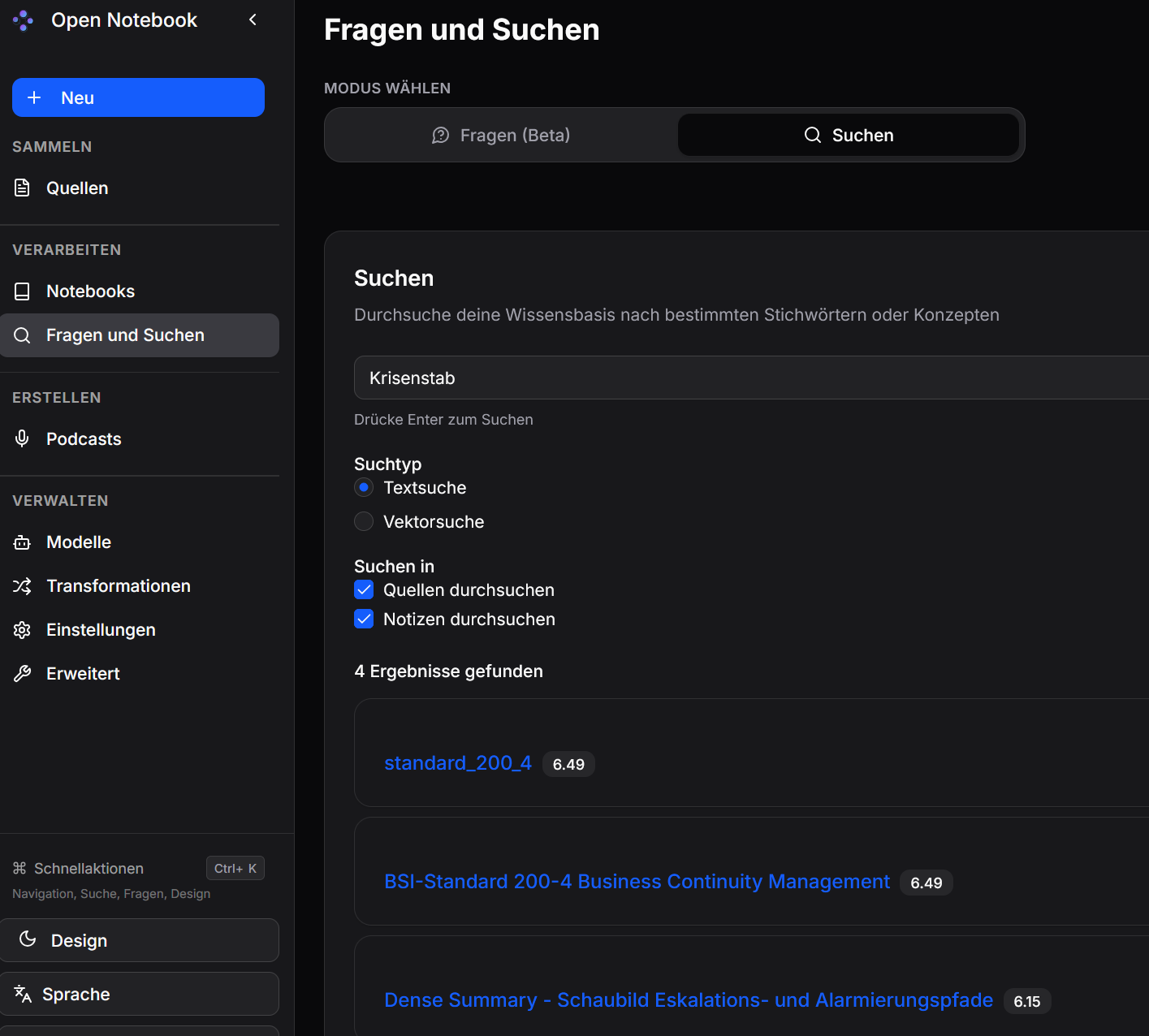
Mit der Option Vektorsuche werden auch semantisch verwandte Begriffe in der Datenbank gefunden und die Quellen gelistet, in denen ein Treffer erfolgte. Die Suche geht über alle Quellen aller Notebooks.
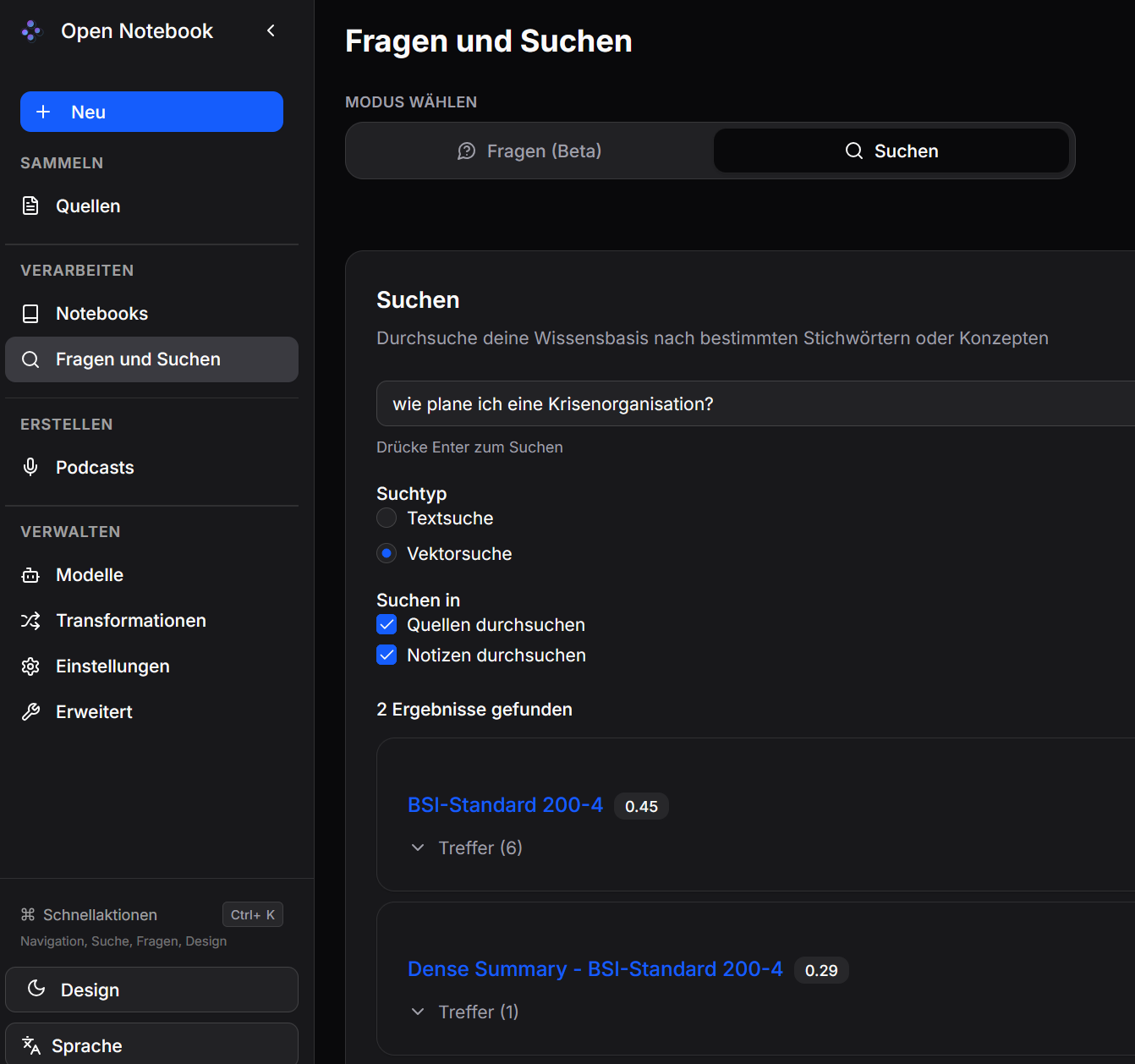
Wissensbasis fragen (Beta)
Mit Fragen kann man sich gezielt Inhalte aufbereiten lassen. Dazu wird ein dreistufiges Verfahren verwendet, bestehend aus
- Strategie
- Antworten
- Zusammengefasste Endantwort
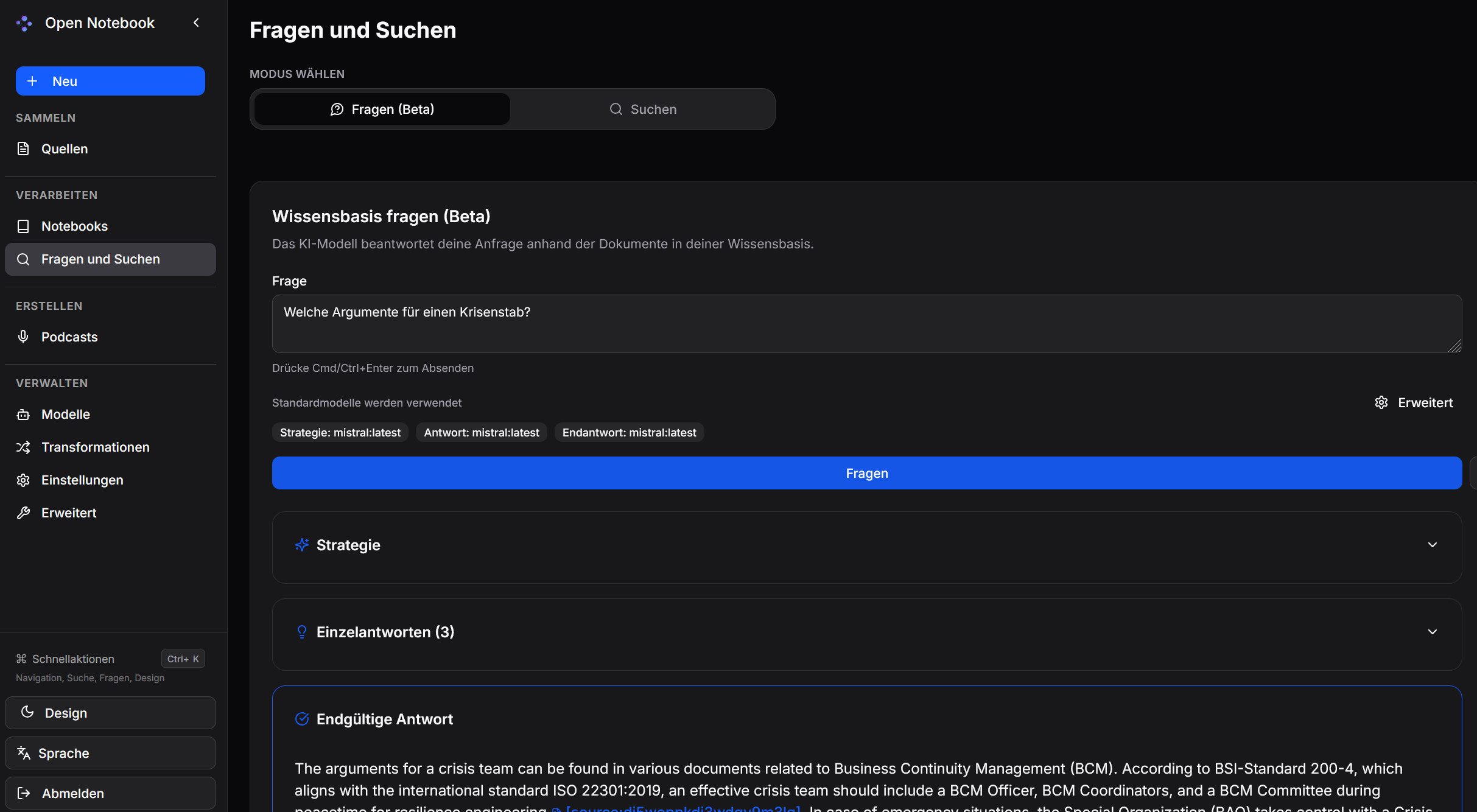
Notizen
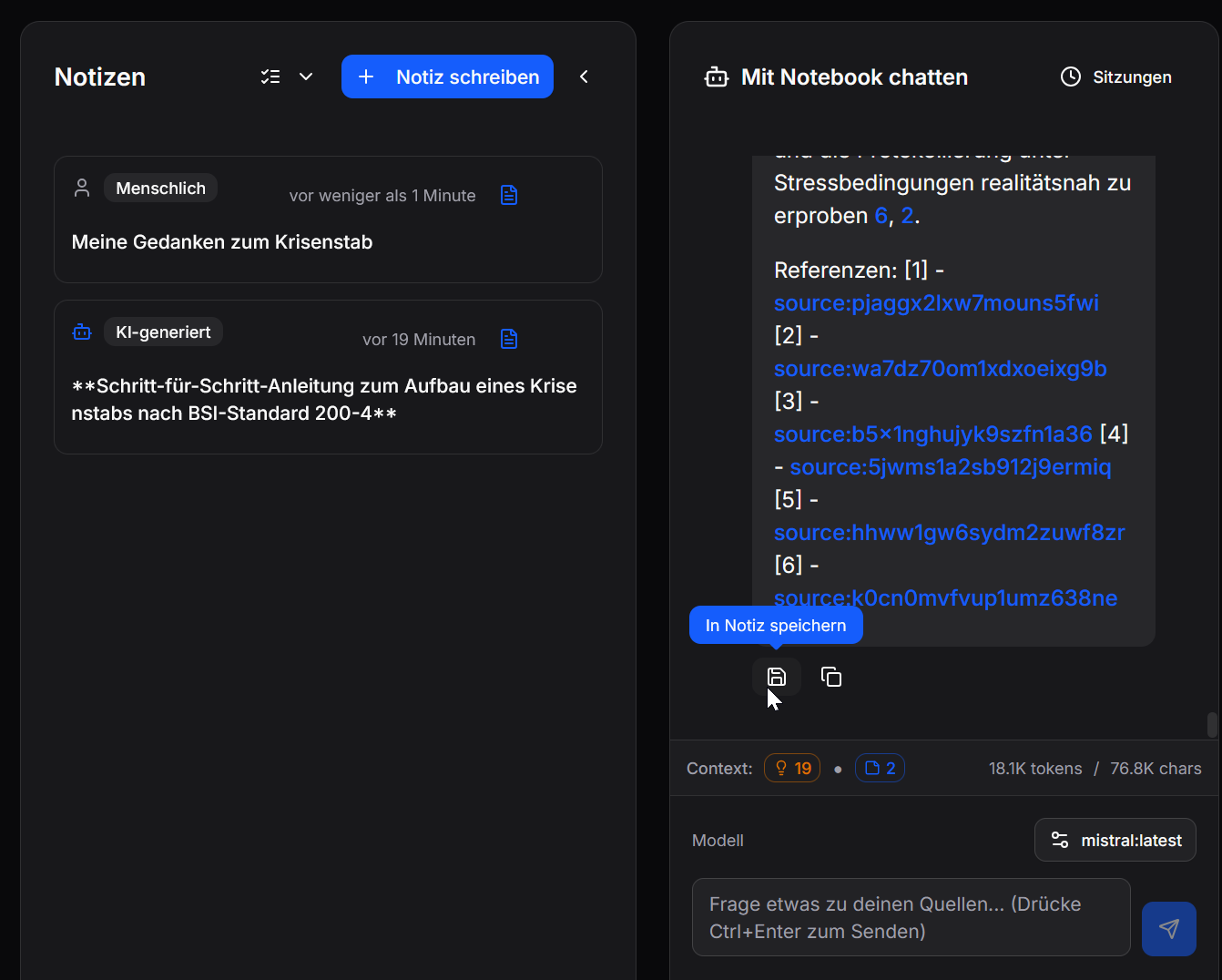
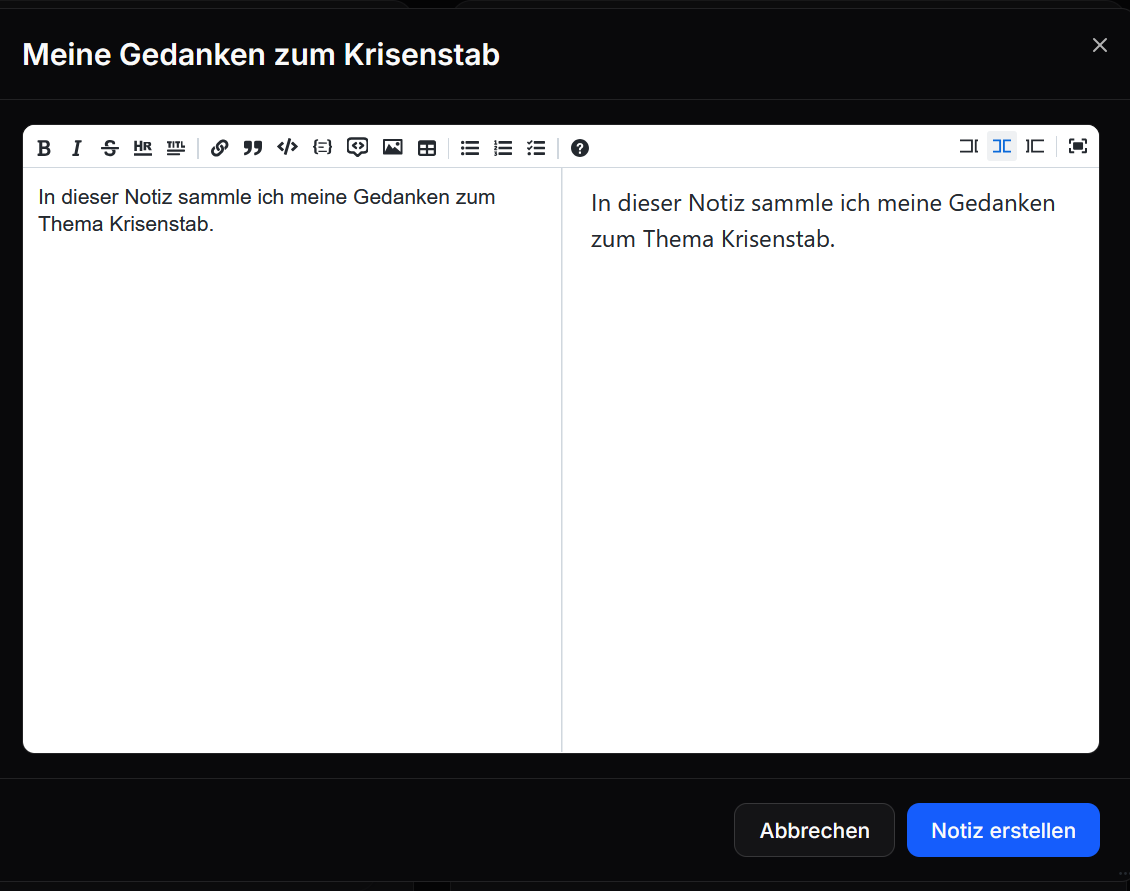
Es gibt 2 Möglichkeiten Notizen zu erstellen:
- Chat als Notiz speichern
- Manuell eine Notiz erstellen
Bei Fragen und Suchen können sowohl Quellen als auch Notizen eingeschloßen werden.
Fazit
Open Notebook liefert für eine Version 1.0 bereits einen guten Start ab. Man kann durchaus damit arbeiten, auch wenn es noch an Feinarbeit und manchen Funktionen fehlt. So ist z.B. das wissenschaftliche Zitieren von Quellen noch rudimentär implementiert. Die Ausgabe von Ergebnissen erfolgt teils noch in Englisch.
Open Notebook verfolgt den Ansatz eine Managementplattform für Wissen zu sein mit eigener lokaler Datenhaltung. Die KI-Komponenten sollen wahlfrei sein, so dass sowohl (kommerzielle) Cloud-KI-Anbieter als auch (freie) lokale KI-Lösungen integriert werden können.
Es empfiehlt sich Testquellen (z.B. URLs und PDFs) in einem Testnotebook anzulegen, um mit diesen verschiedene KI-Tools (für Embedding, Transformation, Suche und Chat) und deren Ergebinsqualität und Ressourcenverbrauch zu evaluieren. Wenn die optimalen Modelle für das eigene System gefunden und in der Konfiguration festgelegt sind können weitere Notebooks angelegt werden.
Weiter gehts mit Audio in Teil 6.
Open Notebook - Teil 4
21. Juni 2026 - Lesezeit: 6 Minuten
Die Oberfläche von Open Notebook kann nun im Browser aufgerufen werden.
Konfiguration der lokalen KI-Modelle für Ollama
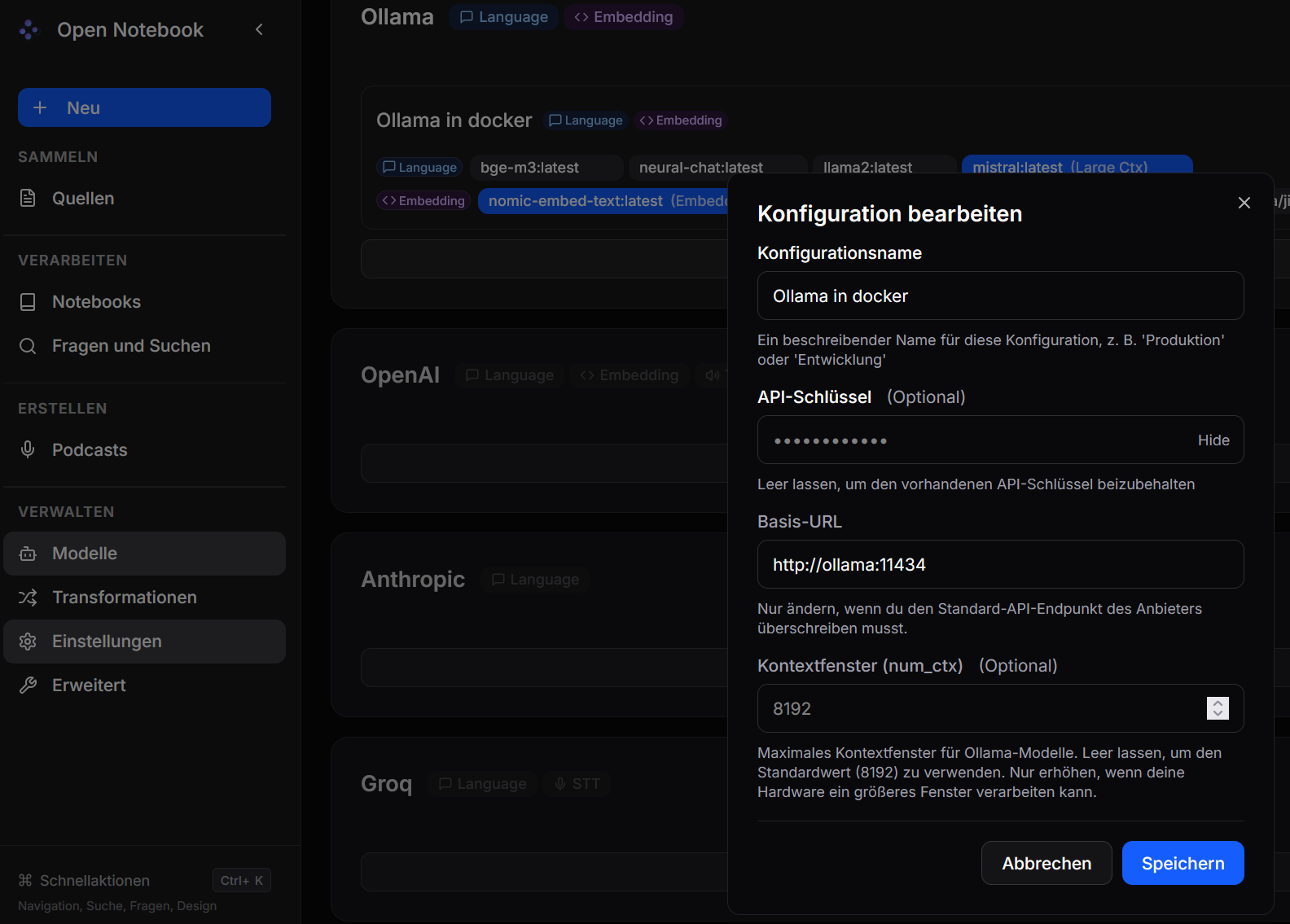
Unter Modelle - Ollama fügt man eine neue Konfiguration hinzu, nennt sie z.B. "Ollama in Docker" und gibt die URL "http://ollama:11434" zum verbinden an.
Das Kontextfenster ist das "Kurzzeitgedächtnis" der KI. Es gibt an, wie viele Wörter oder Zeichen die KI in einem einzigen Durchlauf (z.B. in einem Chat) behalten und verarbeiten kann. Je größer das Fenster, desto mehr Informationen (wie längere Dokumente oder der bisherige Gesprächsverlauf) kann die KI gleichzeitig berücksichtigen.
Wie der Modelltabelle in Teil 3 zu entnehmen ist haben alle Modelle ein Kontextfenster von mindestens 8k bzw. 8192, was der Standardwert in der Konfiguration ist. Bei leistungsstärkerer Hardware und geeignetem Modell kann der Wert erhöht werden.
Danach klickt man im Ollama-Bereich auf Test und ein grüner Haken bescheinigt eine erfolgreiche Verbindung.
Im Anschluß klickt man im Ollama-Bereich auf Models und fügt passende Modelle hinzu.
Zunächst für "language", also Chat...
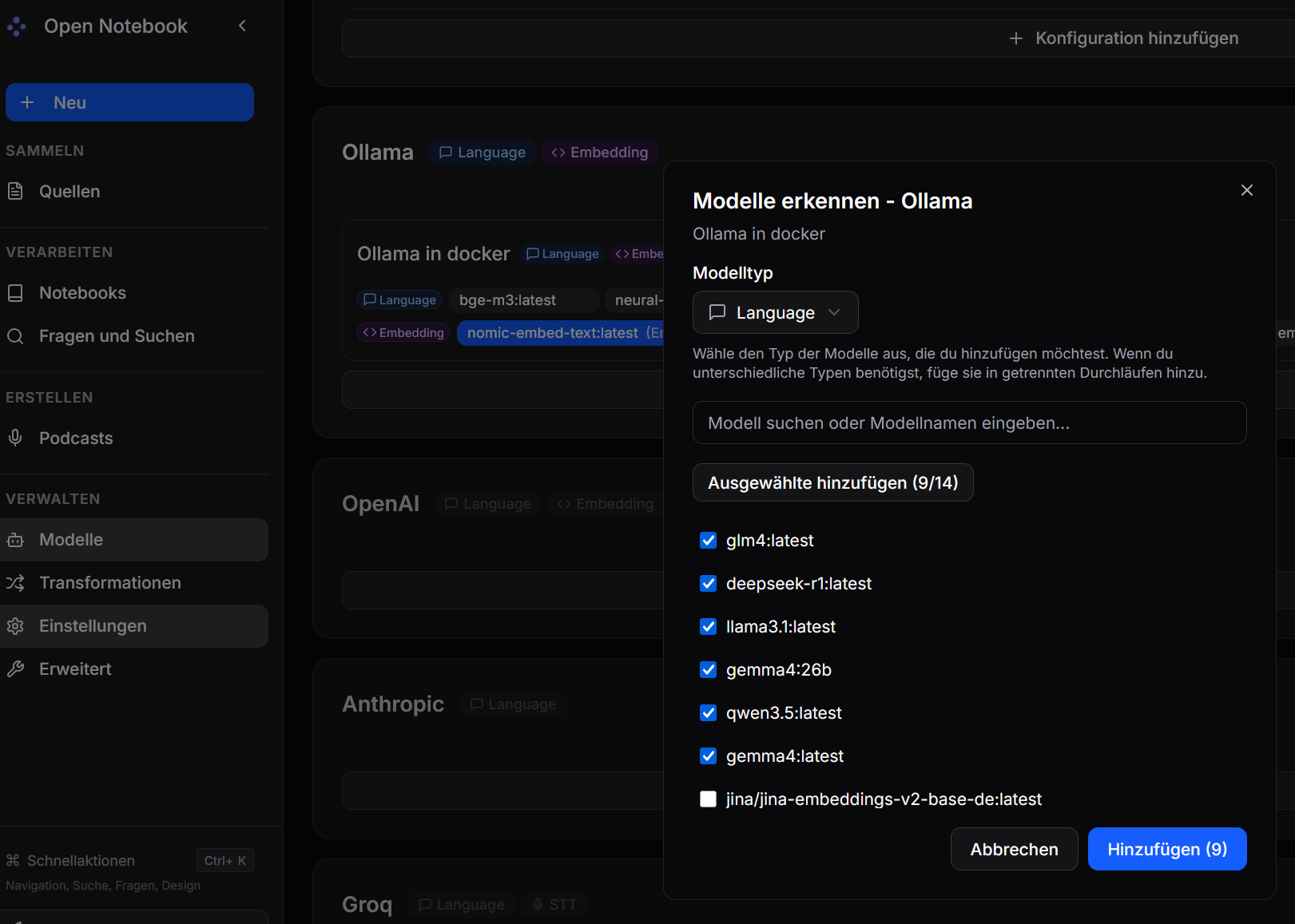
Dann für "Embedding", also Scan von Dokumenten in die Datenbank...
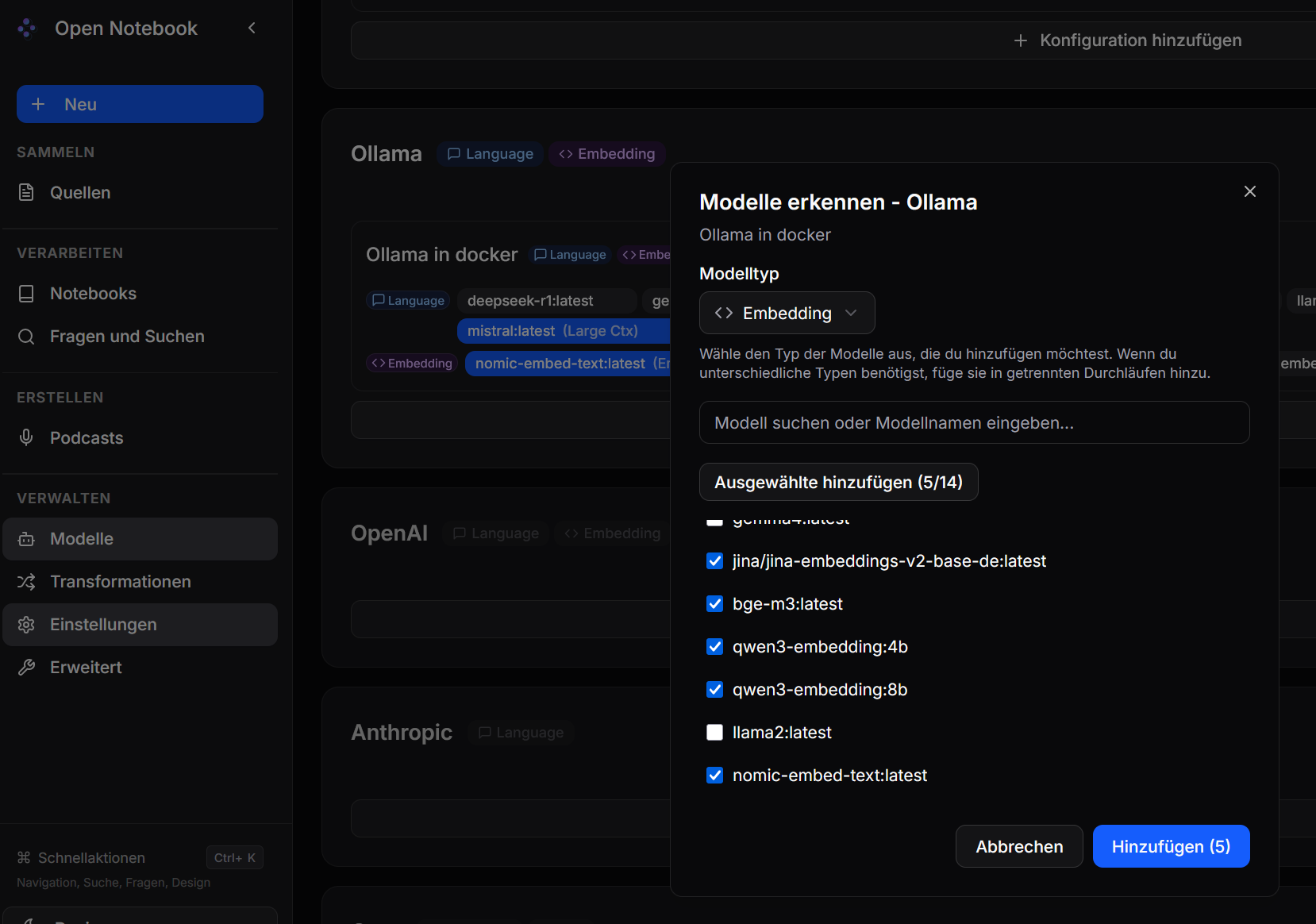
Abschließend kann man das Ergebnis begutachten.
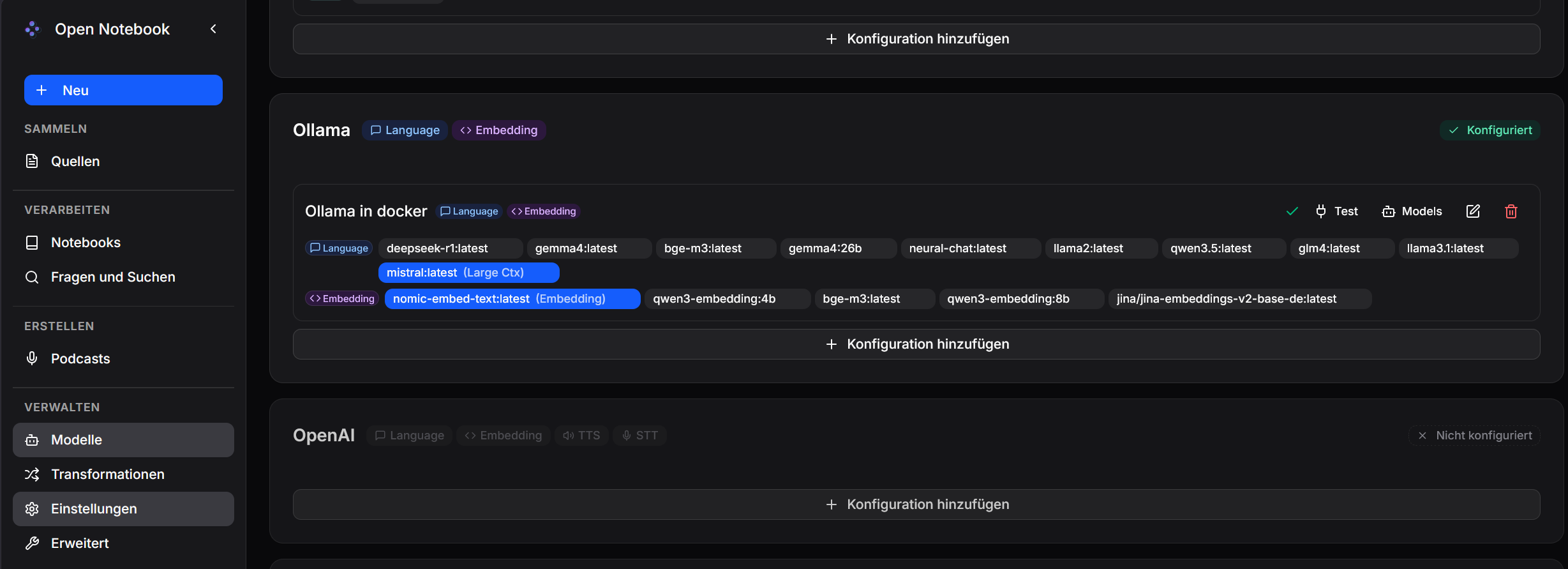
Konfiguration Cloud Ki-Modelle: Google AI
Viele besitzen einen Google Account. Wenn Privatsphäre/Datenschutz nicht im Vordergrund stehen oder man zu Testzwecken z.B. die Leistungsfähigkeit zwischen kommerziellen Cloud KI-Modellen und lokalen freien KI-Modellen anhand eigener Testdaten vergleichen möchte, dann ist das eine weitere Option. Natürlich gibt es in der kostenlosen Variante Limits, die schnell erreicht werden können.
Zunächst muß man sich, falls noch nicht vorhanden, ein Google Konto erstellen und dann in Google AI Studio anmelden. Dort erstellt man ein Projekt und benennt es z.B. "Open Notebook" und erstellt einen API-Key.
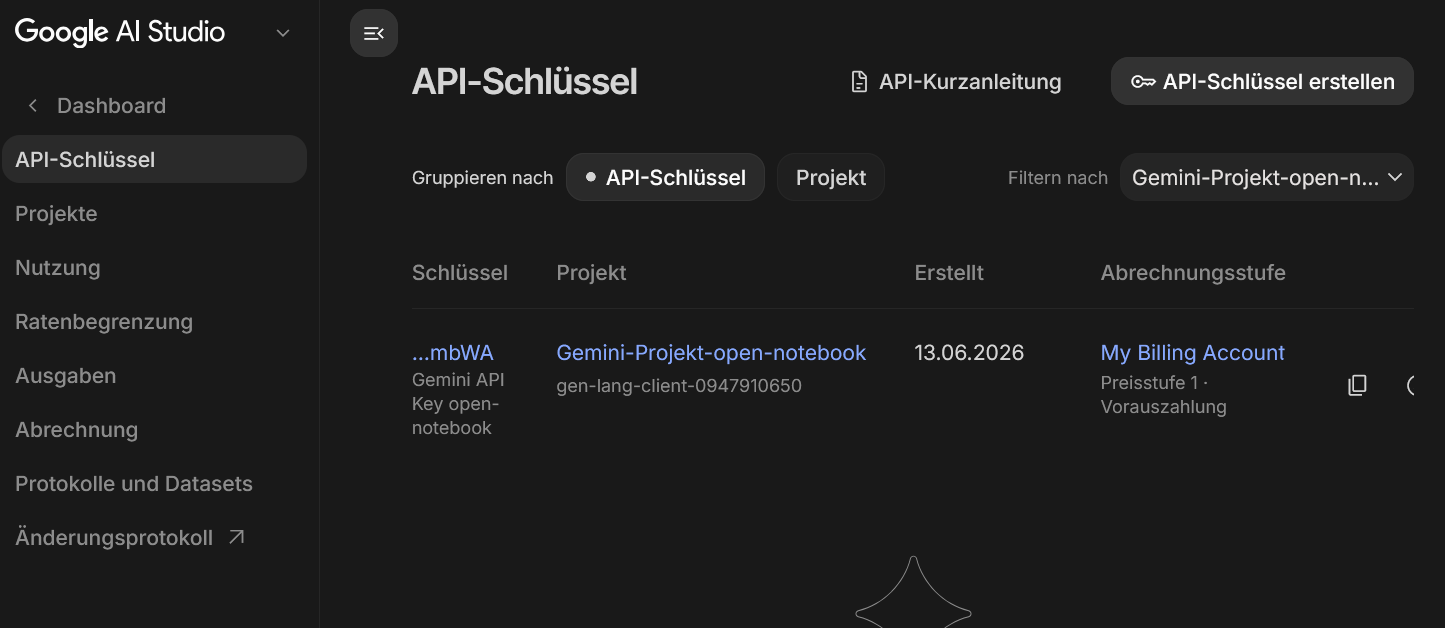
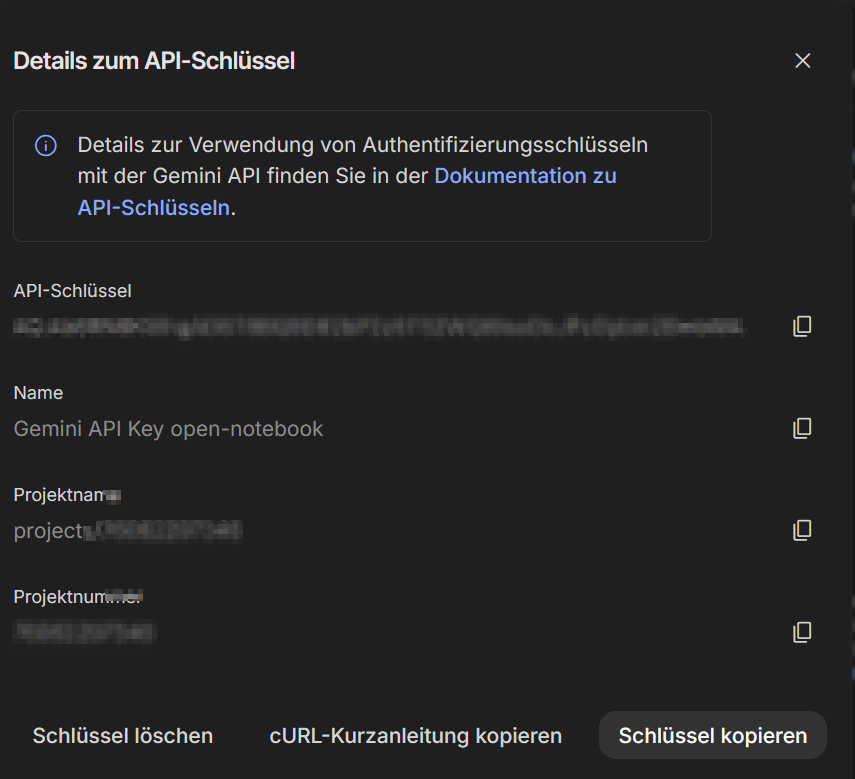
Unter Modelle - Google AI legt man eine neue Konfiguration an, nennt sie z.B. "Gemini API Key open-notebook" und gibt den zuvor erstellten API-Key an. Danach führt man einen Verbindungstest durch.
Mit dem Druck auf models kann man Modelle für Chat und Embedding hinzufügen.

Zuletzt ist noch Modelle - Standardmodell-Zuweisungen einzurichten. D.h. es wird eingestellt für welche Aufgabe welches KI-Modell standardmäßig verwendet werden soll.
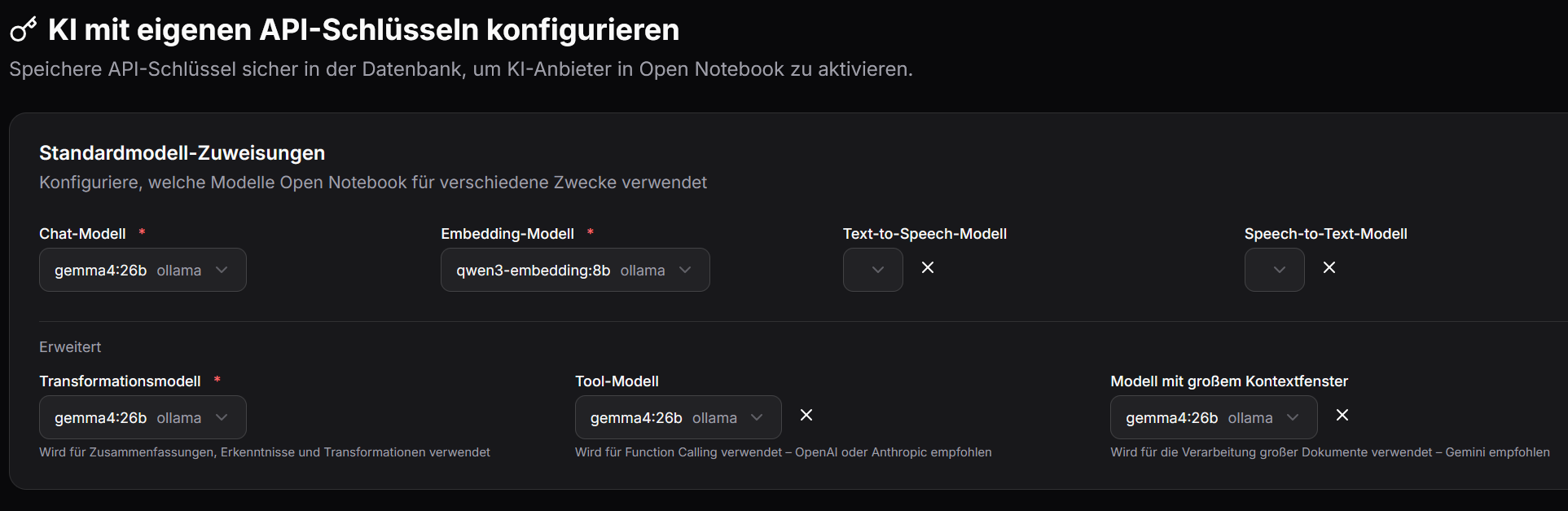
Hinweis
TTS/STT wurde noch nicht konfiguriert.
Weiter gehts mit der Benutzung von Open Notebook in Teil 5.
Open Notebook - Teil 3
21. Juni 2026 - Lesezeit: 16 Minuten
Docker Desktop wird über das Startmenü oder Shell gestartet
systemctl --user start docker-desktop
Die Container sind aufgelistet und im Status erfolgreich gestartet.
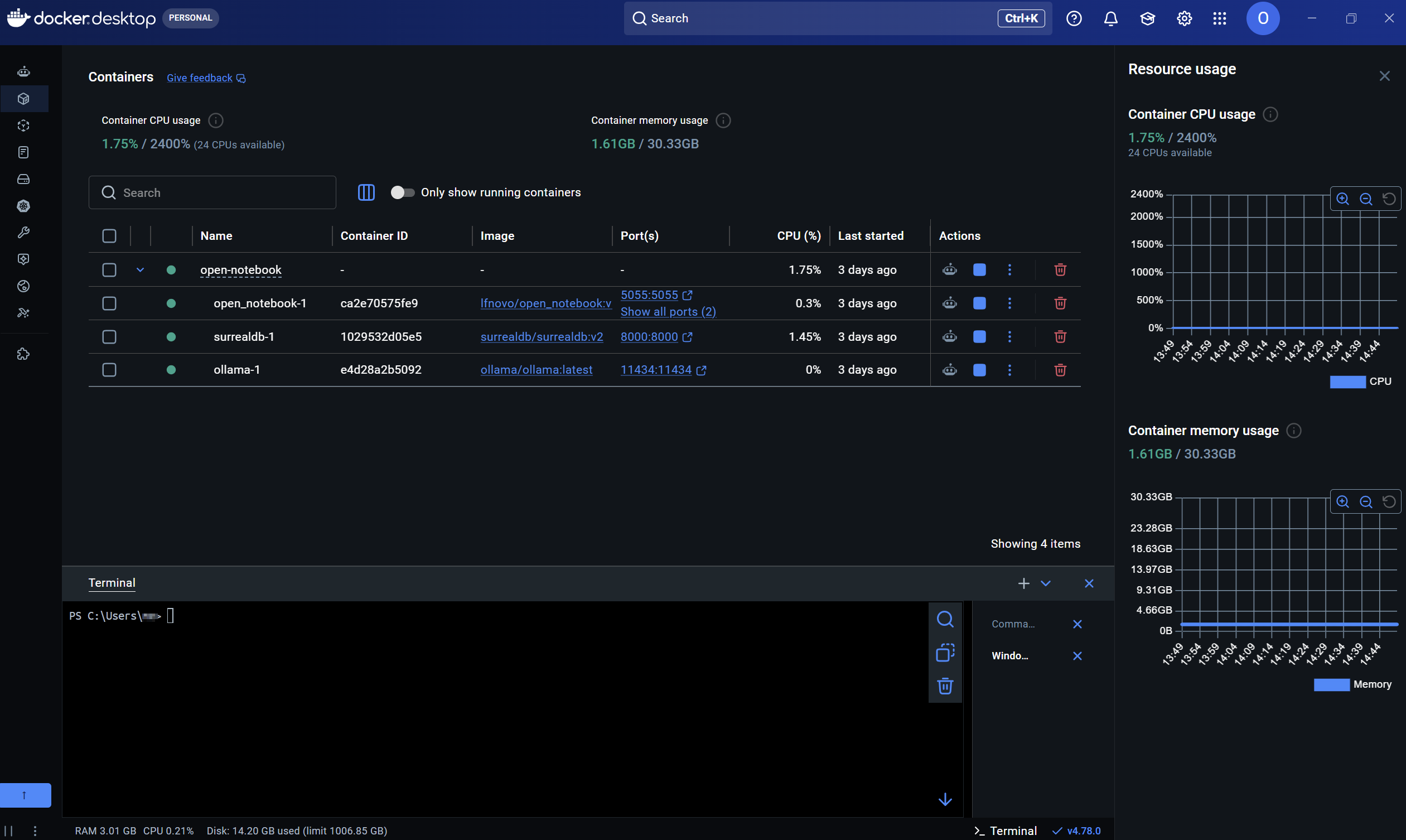
Neben den Containern sind die zugehörigen Portnummer zu sehen (bzw. aufklappbar) und und klickbar.
Ollama
Ollama ist ein lokales KI-Tool, das verschiedene KI-Modelle betreiben kann. In dieser installation wurde Ollama innerhalb eines Docker-Containers gestartet.
KI-Modelle auswählen
Zunächst einmal müssen KI-Modelle für Ollama heruntergeladen und installiert werden. Später können verschiedene KI-Modelle für verschiedene Aufgaben in Open Notebook zugewiesen werden, z.B. Embedding und Chatbot.
Es gibt Modelle unterschiedlicher Hersteller und häufig verschiedene Varianten des selben Modells mit unterschiedlicher Genauigkeit/Qualität (Anzahl Parameter). Dabei erhöht die Wahl eines Modells mit besserer Genauigkeit/Qualität den Bedarf an (V)RAM und die Rechenleistung. Die verwendeten Modelle sollten also passend zur eigenen Rechnerausstattung sein. Die verfügbaren Modelle und Varianten für Ollama können in der Library eingesehen werden. Es gibt unterschiedliche Modelle für unterschiedliche Aufgaben. Multimodale Modelle sind für mehr als eine Aufgabe geeignet, z.B. Text- und Bildanalyse. Auf huggingface können Modelle eingesehen und online getestet werden.
- Allzweck- und Chat-Modelle
Diese Modelle sind wahre Alleskönner. Sie eignen sich hervorragend für allgemeine Fragen, das Zusammenfassen von Texten oder das Befolgen komplexer Anweisungen.- Llama von Meta AI (z.B. Llama 3): Eines der leistungsstärksten Standardmodelle, das eine exzellente Balance zwischen Geschwindigkeit und Qualität bietet.
- Gemma von Google AI (z.B. Gemma 4 / 3): Ein Modell, das besonders schnell ist und sich gut für alltägliche Unterhaltungen und Assistenzaufgaben eignet.
- Qwen von Alibaba Cloud (z.B. Qwen 2.5 / 3): Ein weiteres leistungsstarkes Open-Source-Modell, das bei einer Vielzahl von Aufgaben sehr gut abschneidet.
- Mistral von Mistral AI (z.B. Mistral-Nemo): Hervorragend bei Textübersetzungen, Zusammenfassungen und Logikaufgaben, sehr stark in Deutsch und vielen anderen Sprachen.
- Programmierung (Coding)
Diese Modelle sind speziell darauf trainiert, Quellcode zu verstehen, zu schreiben, zu debuggen und in verschiedenen Programmiersprachen zu optimieren.- Qwen-Coder von Alibaba Cloud (z.B. Qwen3 Coder): Führend in seiner Klasse und exzellent für das Entwickeln ("Vibe Coding") sowie für komplexe Programmieraufgaben.
- DeepSeek von DeepSeek AI (z.B. DeepSeek R1): Sehr stark bei mathematischen und logischen Denkaufgaben sowie der Codegenerierung.
- Codestral von Mistral AI: Reine Spezialisierung auf Programmierung und Code-Generierung, beherrscht über 80 Programmiersprachen.
- Kompakte Modelle
Besonders ressourcenschonende Modelle, die sich hervorragend für ältere Computer, Handys oder den Einsatz als schnelle Hintergrund-KI (z.B. für Smarthome-Befehle) eignen.- Phi von Microsoft (z.B. Phi-4 Mini): Trotz seiner geringen Größe (benötigt nur ca. 4 GB VRAM) verfügt dieses Modell über starke logische Fähigkeiten.
- Qwen-Mini von Alibaba Cloud: Eine kleinere, sehr schnelle Variante der Qwen-Familie.
- Weitere Spezialmodelle
Neben textbasierten Modellen bietet Ollama z.B. auch Unterstützung für sogenannte multimodale Aufgaben.- Vision-Modelle (Qwen-VL von Alibaba Cloud, Llama-Vision von Meta AI): Diese Modelle können neben Text auch Bilder analysieren, beschreiben oder Bildunterschriften generieren.
- Embedding-Modelle (nomic-embed-text von Nomic AI, jina-embeddings-v2-base-de von Jina AI, BGE-M3 von BAAI) erzeugen numerische Vektoren (Zahlenreihen) für Texte, keine Sprachausgaben. Für mehrsprachige oder rein deutsche Texte benötigt man ein geeignetes mehrsprachiges Modell.
- Reasoning-Modelle: Deep Thinking ist eine Funktion die hilft knifflige Probleme zu lösen. Es funktioniert so, dass man mehrere Ideen gleichzeitig mit parallelem Denken durchdenkt, sie vergleicht und dann die beste Lösung auswählt.
- TTS/STT-Modelle (text to speech / Speech to text) für Sprachausgaben müssen als lokale Instalation via OpenAI-kompatibler API angebunden werden. Ollama unterstützt das nicht. Man braucht dazu einen weiteren Container z.B. mit speaches-ai.
- Mixture of Experts Modelle: MoE ist eine KI-Architektur, bei der ein großes neuronales Netz in viele kleine, spezialisierte Teilnetze (die "Experten") unterteilt wird. Ein Steuerungsmechanismus (der "Router") leitet jede Anfrage dynamisch nur an die Experten weiter, die für das jeweilige Problem am besten geeignet sind.
- Tools (Function Calling) ist die Fähigkeit eines Sprachmodells selbstständig Programme, APIs, Webseiten oder andere externe Skripte auszuführen, anstatt nur Text zu generieren
- MLX ist Apples eigenes Machine-Learning-Framework. Modelle mit MLX im Namen sind für Apple Silicon CPUs.
Open Notebook verwendet Esperanto zur Anbindung der verschiedener KI-Provider. Es gibt eine Übersicht, welche Anbieter/Modelle welche Aufgaben (Embedding, Chat, TTS, STT) erledigen können. Da mit Ollama keine Audio Ein- oder Ausgabe angebunden werden kann wird Audio erstmal vertagt.
|
Ollama Modellname |
Hersteller | Herkunft | Features | Parameter | Kontext | Größe | Kommentar |
| mistral | Mistral AI | Frankreich | tools | 7b | 32K | 4,4GB | Open Notebook Doku: Fastest & smallest (recommended for testing) |
| neural-chat | Intel | USA | 7b | 32K | 4,1GB | Open Notebook Doku: Better quality but slower | |
| llama2 | Meta AI | USA | 7b | 4K | 3,8GB | Open Notebook Doku: Even better quality, more VRAM needed | |
| qwen3-embedding:4b | Alibaba Cloud | China | embedding | 4b | 32K | 2,5GB | für RAG (Dokumente in Datenbank scannen) |
| qwen3-embedding:8b | Alibaba Cloud | China | embedding | 8b | 32K | 4,7GB | für RAG (Dokumente in Datenbank scannen) |
| bge-m3 | BAAI | China | embedding | 0,6b | 8K | 1,2GB | für RAG (Dokumente in Datenbank scannen) |
| jina-embeddings-v2-base-de | Jina AI | Deutschland | embedding | 0,2b | 8K | 0,3GB | für RAG (Dokumente in Datenbank scannen) |
| gemma4 | Google AI | USA | vision, tools, thinking, audio | e4b | 128K | 9,6GB | für Chat, Suche |
| gemma4:26b | Google AI | USA | vision, tools, thinking, audio | 26b | 256K | 18GB | für Chat, Suche, MoE Modell mit 4B aktive Parameter |
| deepseek-r1 | DeepSeek AI | China | tools, thinking | 8b | 128K | 5,2GB | für Chat, Suche |
| llama3.1 | Meta AI | USA | tools | 8b | 128K | 4,9GB | für Chat, Suche |
| qwen3.5 | Alibaba Cloud | China | vision, tools, thinking | 9b | 256K | 6,6GB | für Chat, Suche |
| glm4 | Zhipu AI | China | 9b | 128K | 5,5GB | für Chat, Suche |
Man sollte mindestens ein auf Chat/Suche und ein auf Embedding optimiertes Modell herunterladen. Dabei ist zu beachten, wie viel freier (V)RAM auf der eigenen Hardware zur Verfügung steht.
KI-Modelle installieren
- Empfehlung für kleine Hardwareausstattung ~4,7GB (V)RAM:
docker exec open-notebook-ollama-1 ollama pull jina/jina-embeddings-v2-base-de
docker exec open-notebook-ollama-1 ollama pull mistral
- Empfehlung für mittlere Genauigkeit/Qualität ~7,8GB (V)RAM:
docker exec open-notebook-ollama-1 ollama pull bge-m3
docker exec open-notebook-ollama-1 ollama pull qwen3.5
- Empfehlung für hohe Genauigkeit/Qualität ~12,1GB (V)RAM:
docker exec open-notebook-ollama-1 ollama pull qwen3-embedding:4b
docker exec open-notebook-ollama-1 ollama pull gemma4
- Empfehlung für höchste Genauigkeit/Qualität ~22,7GB (V)RAM:
docker exec open-notebook-ollama-1 ollama pull qwen3-embedding:8b
docker exec open-notebook-ollama-1 ollama pull gemma4:26b
GPU-Nutzung überprüfen
Wenn in der Ollama-Docker-Konfiguration die Unterstützung für NVidia-GPUs aktiviert wurde kann die Funktionalität überprüft werden. Bei der Ollama-Prozessübersicht muß die Spalte PROCESSOR mit GPU gefüllt sein.
docker exec open-notebook-ollama-1 ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
llama2:latest 78e26419b446 6.0 GB 100% GPU 4096 3 minutes from now
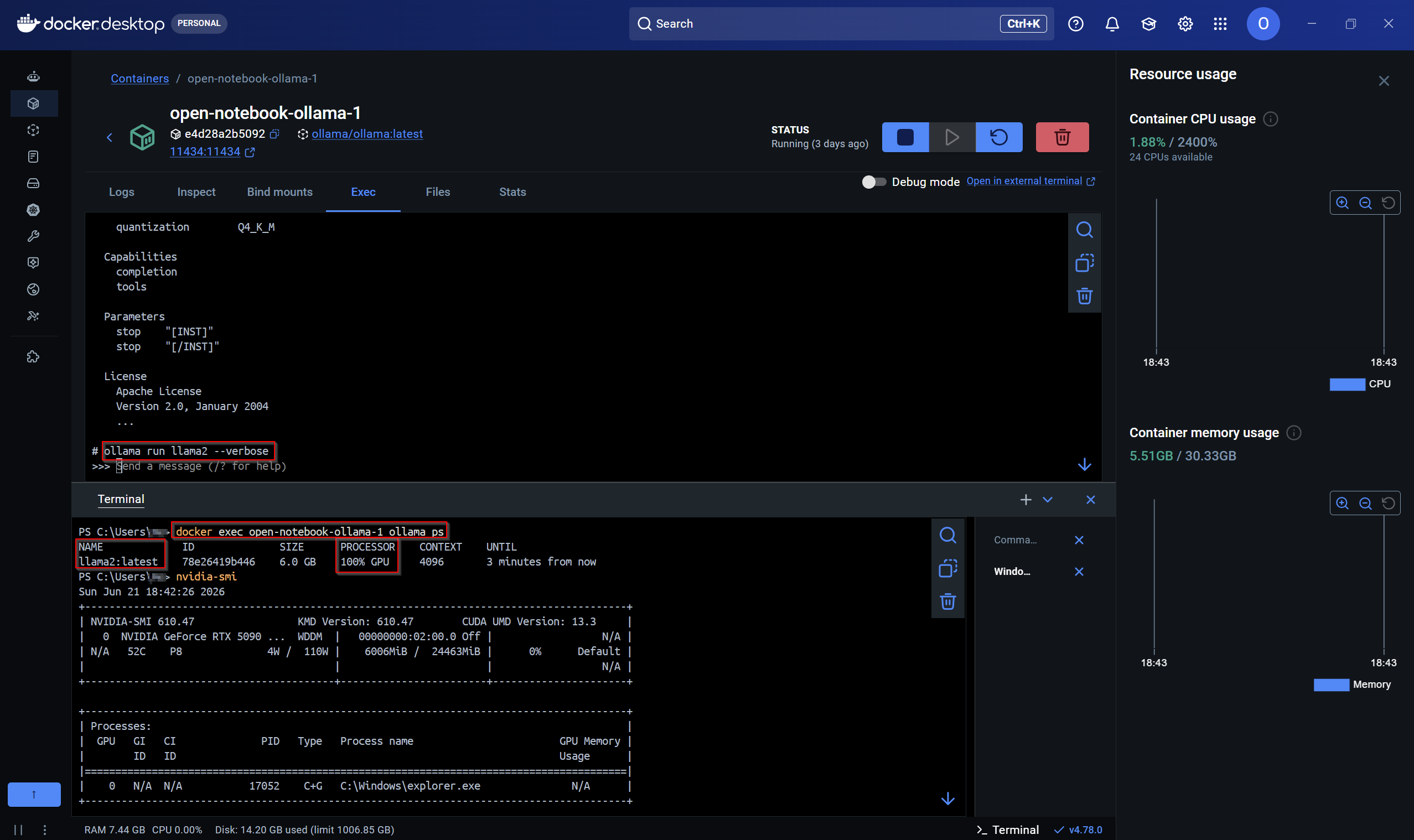
Die Abfrage kann auch direkt in Docker Desktop erfolgen.
Weiter gehts mit der Konfiguration in Teil 4.
Docker
21. Juni 2026 - Lesezeit: 5 Minuten
Docker ist eine freie Software zur Isolierung von Anwendungen mit Hilfe von Containervirtualisierung.
Das ist eine ressourcensparsame Variante der Virtualisierung, bei der sich die Container den Betriebssystemkern mit dem Hauptsystem teilen. Im Wesentlichen werden dabei die Prozesse der Container durch Betriebssystemfunktionen abgeschottet und Zugriffe beschränkt. Die Bereitstellung von Anwendungen in Containern erfolgt über Image- und Konfigurationsdateien. Bei Updates wird einfach das Image ausgetauscht. Das Installaieren und Aktualisieren von Applikationscontainern erscheint Vielen als deutlich leichter, als Applikationen nativ im Betriebssystem bereitzustellen. Das liegt daran, dass alle benötigten Dateien in passender Version im Container-Image enthalten sind, d.h. keine Probleme mit Abhängigkeiten.
Unter Linux steht die freie Docker Engine (Docker CE) standardmäßig zur Installation Verfügung, die über Kommandozeile bedient wird.
Docker Desktop bietet eine Bedienoberfläche, steht für verschiedene Betriebssysteme zur Verfügung und ist für den privaten Gebrauch kostenlos. Für Einsteiger in Containervirtualisierung empfiehlt sich diese Variante.
Installation von Docker Desktop
Ubuntu Linux
Die Installation von Docker Desktop für Ubuntu läuft wie folgt ab:
sudo apt-get update
sudo apt install gnome-terminal
Docker Desktop für Linux deb-Paket herunterladen.
sudo apt install ./docker-desktop-amd64.deb
Docker Desktop startet man aus dem Startmenü oder via Shell:
systemctl --user start docker-desktop
Debian Linux
Die Installation von Docker Desktop für Debian läuft identisch wie bei Ubuntu ab.
Fedora Linux
Die Installation von Docker Desktop für Fedora läuft wie folgt ab:
sudo dnf install gnome-terminal
sudo dnf config-manager addrepo --from-repofile https://download.docker.com/linux/fedora/docker-ce.repo
Docker Desktop für Linux rpm-Paket herunterladen.
sudo dnf install ./docker-desktop-x86_64.rpm
Docker Desktop startet man aus dem Startmenü oder via Shell:
systemctl --user start docker-desktop
Windows
Die Installation von Docker Desktop für Windows läuft wie folgt ab:
Als Voraussetzung muss entweder WSL2, Hyper-V oder Virtualbox in Windows installiert sein. Das liegt daran, dass zum Betrieb ein Linux-Betriebssystemkern benötigt wird. Als ressourcenschonende Variante hat sich WSL2 bewährt. Die Installation wurde bereits in einem Artikel beschrieben.
Zunächst lädt man Docker Desktop für Windows x86_64 herunter und installiert "Docker Desktop Installer.exe". Bei der Installation wählt man WSL2 als Konfigurationsoption aus.
Nach der Installation kann man in der Powershell überprüfen, ob eine Linux Instanz für Docker angelegt wurde:
wsl --list
Windows Subsystem für Linux-Distributionen:
Ubuntu (Standard)
docker-desktop
MacOs
Für die Installation von Docker Desktop für Mac folgt man der Anleitung. Zu beachten sind dabei benötigte Berechtigungen.
Screenshot von Docker Desktop mit laufenden Containern der App Open Notebook:

WSL2 für Windows 11
21. Juni 2026 - Lesezeit: 4 Minuten
Mit dem Windows-Subsystem für Linux (WSL) können Windows-Anwender eine Linux-Distribution (z.B. Ubuntu, OpenSUSE, Kali, Debian, Arch Linux usw.) installieren und Linux-Anwendungen, Dienstprogramme und Bash-Befehlszeilentools direkt unter Windows verwenden, ohne den Aufwand eines herkömmlichen virtuellen Computers oder Dual Boot Setups.Der Ressourcenverbrauch für WSL2 ist gering.
WSL2 installieren:
PowerShell im Administratormodus öffnen (mit Rechtsklick auf Icon)
wsl --install
Verfügbare Distributionen auflisten:
wsl --list --online
Im Folgenden finden Sie eine Liste gültiger Distributionen, die installiert werden können.
Mit "wsl.exe --install <Distro>" installieren.
NAME FRIENDLY NAME
Ubuntu Ubuntu
Ubuntu-26.04 Ubuntu 26.04 LTS
Ubuntu-24.04 Ubuntu 24.04 LTS
Ubuntu-22.04 Ubuntu 22.04 LTS
openSUSE-Tumbleweed openSUSE Tumbleweed
openSUSE-Leap-16.0 openSUSE Leap 16.0
SUSE-Linux-Enterprise-15-SP7 SUSE Linux Enterprise 15 SP7
SUSE-Linux-Enterprise-16.0 SUSE Linux Enterprise 16.0
kali-linux Kali Linux Rolling
Debian Debian GNU/Linux
AlmaLinux-8 AlmaLinux OS 8
AlmaLinux-9 AlmaLinux OS 9
AlmaLinux-Kitten-10 AlmaLinux OS Kitten 10
AlmaLinux-10 AlmaLinux OS 10
archlinux Arch Linux
FedoraLinux-44 Fedora Linux 44
FedoraLinux-43 Fedora Linux 43
eLxr eLxr 12.12.0.0 GNU/Linux
OracleLinux_7_9 Oracle Linux 7.9
OracleLinux_8_10 Oracle Linux 8.10
OracleLinux_9_5 Oracle Linux 9.5
SUSE-Linux-Enterprise-15-SP6 SUSE Linux Enterprise 15 SP6
Distribution aus obiger Liste installieren, z.B. Ubuntu:
wsl --install -d Ubuntu
Installierte Distributionen anzeigen:
wsl --list
Windows Subsystem für Linux-Distributionen:
Ubuntu (Standard)
FedoraLinux-44
openSUSE-Tumbleweed
kali-linux
docker-desktop
In Linux auf der Shell wechseln:
PS C:\Users\xxx> wsl
xxx@pcxxx:/mnt/c/Users/xxx$ uname -a
Linux pcxxx 6.18.33.1-microsoft-standard-WSL2 #1 SMP PREEMPT_DYNAMIC Fri Jun 5 01:12:21 UTC 2026 x86_64 GNU/Linux
xxx@pcxxx:/mnt/c/Users/xxx$ cat /etc/*release*
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=26.04
DISTRIB_CODENAME=resolute
DISTRIB_DESCRIPTION="Ubuntu 26.04 LTS"
PRETTY_NAME="Ubuntu 26.04 LTS"
NAME="Ubuntu"
VERSION_ID="26.04"
VERSION="26.04 (Resolute Raccoon)"
VERSION_CODENAME=resolute
ID=ubuntu
ID_LIKE=debian
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
UBUNTU_CODENAME=resolute
LOGO=ubuntu-logo
Der Zugriff auf Dateien des jeweiligen Systems ist problemlos möglich:
- Im Windows Explorer ruft man \\wsl.localhost\Ubuntu auf um auf das Dateisystem der Distribution Ubuntu zuzugreifen.
- Unter Linux greift man auf /mnt/c zu, wenn man die Partition c:\ aufrufen will.
Selbst die Ausgabe grafischer Fenster ist mittlerweile möglich.

WSL2 ist auch standardmäßig die Voraussetzung für die Installation von Docker Desktop auf Windows.